
Un nuovo metodo innovativo è stato sviluppato dagli scienziati per svelare il processo decisionale dei deep neural networks, portando finalmente alla luce il modo in cui queste intelligenze artificiali pensano. Questo approccio rivoluzionario permette di visualizzare come l’intelligenza artificiale organizza i dati in categorie, garantendo una maggiore sicurezza e affidabilità per applicazioni reali come la sanità e le auto a guida autonoma. Grazie a questo progresso, ci avviciniamo sempre di più a comprendere appieno il funzionamento dell’intelligenza artificiale.
I deep neural networks rappresentano una forma di intelligenza artificiale progettata per emulare il modo in cui il cervello umano elabora le informazioni.
Tuttavia, il processo decisionale di queste reti è stato a lungo un enigma per i ricercatori. Recentemente, un team di esperti dell’Università di Kyushu ha introdotto un nuovo metodo per analizzare in modo più approfondito come i deep neural networks interpretano e categorizzano i dati. I risultati di questa ricerca, pubblicati su IEEE Transactions on Neural Networks and Learning Systems, mirano a potenziare l’accuratezza, l’affidabilità e la sicurezza dell’intelligenza artificiale.
- Analogamente al modo in cui gli esseri umani risolvono i puzzle passo dopo passo, i deep neural networks elaborano le informazioni attraverso diversi livelli di elaborazione.
- Il primo livello, noto come livello di input, acquisisce i dati grezzi, mentre i livelli successivi, chiamati livelli nascosti, analizzano i dati in fasi.
- I primi livelli nascosti individuano caratteristiche elementari come bordi o texture, simili all’identificazione di singoli pezzi di un puzzle.
Man mano che si procede nei livelli più profondi, queste caratteristiche vengono combinate per riconoscere pattern più complessi, come ad esempio distinguere tra un gatto e un cane, simile a comporre i pezzi di un puzzle per ottenere un’immagine completa.
Tuttavia, i livelli nascosti di queste reti sono come scatole nere sigillate: osserviamo l’input e l’output, ma il processo interno rimane oscuro.
Come sottolinea Danilo Vasconcellos Vargas, Professore Associato della Facoltà di Scienze dell’Informazione e Ingegneria Elettrica dell’Università di Kyushu, questa mancanza di trasparenza diventa critica quando l’intelligenza artificiale commette errori, anche a causa di variazioni minime come la modifica di un singolo pixel. È fondamentale comprendere il processo decisionale dell’IA per garantirne l’affidabilità, nonostante la sua apparente intelligenza.
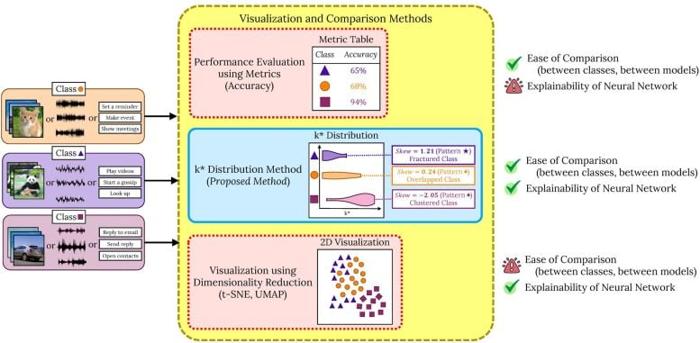
- Attualmente, i metodi di visualizzazione dell’organizzazione dei dati da parte dell’intelligenza artificiale si basano sulla semplificazione dei dati ad alta dimensionalità in rappresentazioni 2D o 3D.
- Tuttavia, questa semplificazione presenta limitazioni significative, poiché la riduzione delle dimensioni comporta la perdita di dettagli cruciali e rende difficile il confronto tra diversi neural networks o classi di dati.
Per affrontare questa sfida, i ricercatori hanno introdotto il metodo di distribuzione k*, che consente di visualizzare in modo più chiaro come i deep neural networks categorizzano gli elementi correlati. Questo approccio assegna a ciascun punto dati un valore k*, indicando la distanza dal punto dati non correlato più vicino, offrendo una visione dettagliata dell’organizzazione dei dati senza perdere informazioni.
Utilizzando il metodo di distribuzione k*, i ricercatori hanno identificato che i deep neural networks organizzano i dati in disposizioni raggruppate, fratturate o sovrapposte.
Le disposizioni raggruppate indicano che gli elementi simili sono vicini tra loro, mentre quelli non correlati sono chiaramente separati, evidenziando una buona capacità di ordinamento dell’IA. Al contrario, le disposizioni fratturate e sovrapposte indicano una dispersione degli elementi simili o una sovrapposizione tra elementi non correlati, aumentando il rischio di errori di classificazione. Questo approccio è paragonabile a un sistema di magazzino: un’organizzazione efficace facilita il recupero degli elementi, mentre una disposizione disordinata rende più difficile trovare ciò che si cerca.
- L’intelligenza artificiale è sempre più presente in settori critici come i veicoli autonomi e la diagnostica medica, dove l’accuratezza e l’affidabilità sono fondamentali.
- Il metodo di distribuzione k* fornisce un valido strumento per valutare come l’IA organizza e classifica le informazioni, individuando potenziali punti deboli o errori.
Questo approccio non solo supporta i processi di regolamentazione necessari per l’integrazione sicura dell’IA nella società, ma fornisce anche preziose informazioni su come l’IA prende decisioni. Identificando le cause degli errori, i ricercatori possono perfezionare i sistemi di intelligenza artificiale per renderli più precisi e robusti, in grado di gestire dati imperfetti e adattarsi a situazioni impreviste.
In conclusione, il metodo di distribuzione k* rappresenta un passo avanti significativo nel campo della comprensione del processo decisionale dei deep neural networks.
Questo approccio innovativo non solo migliora la trasparenza e l’efficacia dell’intelligenza artificiale, ma fornisce anche importanti indicazioni per sviluppare sistemi più affidabili e precisi, in grado di affrontare le sfide del mondo reale.






