I nostri registri del genoma umano potrebbero ancora nascondere decine di migliaia di ‘geni oscuri’, sequenze genetiche difficili da individuare che potrebbero codificare per piccole proteine. Queste proteine sono coinvolte in processi legati a malattie come il cancro e l’immunologia, come confermato da un consorzio globale di ricercatori.
Queste scoperte potrebbero spiegare perché le stime precedenti sulla dimensione del nostro genoma erano molto più ampie rispetto a quanto rivelato dal Progetto Genoma Umano 20 anni fa. Il nuovo studio internazionale, ancora in fase di revisione tra pari, mette in luce come la nostra comprensione dei geni umani sia in costante evoluzione.
Caratteristiche genetiche più sottili vengono scoperte grazie ai progressi tecnologici e all’esplorazione continua che mette in luce lacune ed errori nei registri. Questi geni trascurati sono rimasti nascosti in regioni del DNA precedentemente considerate non codificanti per proteine, una volta definite come ‘DNA spazzatura’.
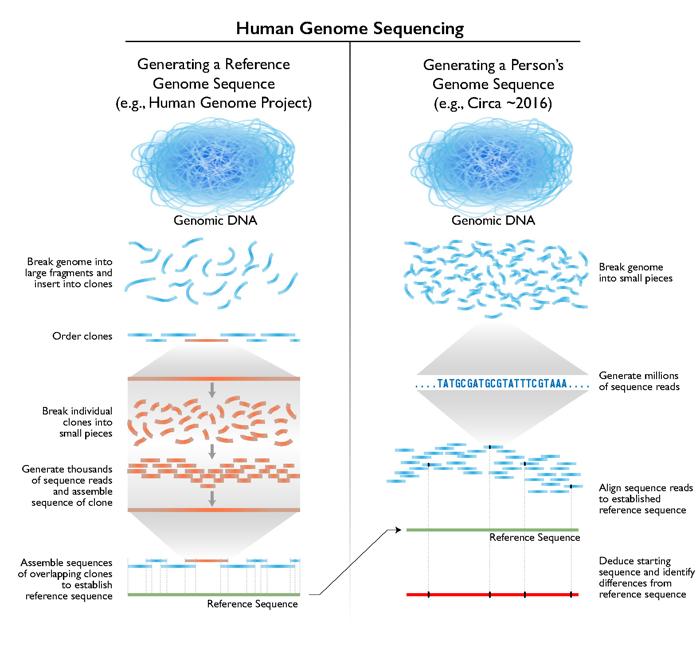
Il proteomicista Eric Deutsch dell’Istituto di Biologia dei Sistemi e il suo team hanno individuato una grande quantità di questi ‘geni oscuri’ analizzando dati genetici provenienti da 95.520 esperimenti. Questi includono studi che utilizzano la spettrometria di massa per investigare piccole proteine, nonché cataloghi di frammenti proteici rilevati dai nostri sistemi immunitari.
Questi ‘geni oscuri’ sono caratterizzati da versioni più brevi rispetto ai tradizionali codici di avvio genico, il che potrebbe aver contribuito a trascurarli in passato. Nonostante le loro sequenze di avvio non convenzionali, i geni del frame di lettura aperto non canonico (ncORF) vengono comunque utilizzati come modello per creare RNA e, successivamente, piccole proteine composte da pochi amminoacidi.
Studi precedenti hanno dimostrato che le cellule tumorali contengono centinaia di queste piccole proteine, il che sottolinea l’importanza di identificarle. Queste nuove proteine ncORF potrebbero avere un impatto biomedico significativo, suscitando un crescente interesse nell’ambito dell’immunoterapia del cancro, comprese terapie cellulari e vaccini terapeutici.
Alcuni di questi geni che codificano peptidi criptici sono trasposoni, elementi mobili che si spostano nei nostri genomi, inclusi segmenti inseriti da virus. Altri sono considerati aberranti, poiché alcune delle proteine individuate tramite spettrometria di massa sono state trovate solo in campioni di cancro, suggerendo un’origine non naturale.
Dei 7.264 set di geni non canonici identificati, almeno un quarto potrebbe dar luogo alla produzione di proteine. Questo ha portato alla scoperta di almeno 3.000 nuovi geni codificanti peptidi da aggiungere al Genoma Umano, con la possibilità che ce ne siano decine di migliaia ancora da identificare.
Queste nuove scoperte potrebbero aprire la strada a una nuova classe di bersagli farmacologici per i pazienti, come sottolineato dal neurooncologo John Prensner dell’Università del Michigan. Gli strumenti sviluppati dal team aiuteranno altri ricercatori a esplorare ulteriormente questa intricata materia genetica.
Questa ricerca, attualmente in fase di revisione tra pari su bioRxiv, getta nuova luce su un aspetto finora poco conosciuto del nostro genoma, aprendo nuove prospettive per la ricerca biomedica e terapeutica. Inoltre, i geni del frame di lettura aperto non canonico (ncORF) sono stati oggetto di studi recenti, come evidenziato in questo articolo di Nature Biotechnology, che discute la loro importanza per la sopravvivenza delle cellule tumorali.